1. What is FastGS?
TL;DR: FastGS is a new, simple, and general acceleration framework for 3D Gaussian Splatting (3DGS). It enables training a scene in about 100 seconds while maintaining comparable rendering quality.
The core idea is to combine multi-view consistent densification and targeted pruning, which together reduce unnecessary computation while preserving visual fidelity.
- Fast: 2–7× training acceleration across varied backbones.
- Accurate: Comparable or better rendering quality versus prior Gaussian-based methods.
- Versatile: Applicable to dynamic scenes, surface reconstruction, sparse-view setups, large-scale reconstruction and SLAM.
2. Training Process Visualization
We demonstrate how FastGS accelerates the training process of different backbones on various scenes.
2.1 Outperform SOTA
FastGS surpasses state-of-the-art Gaussian-based rendering methods in both reconstruction quality and training speed.
Fullscreen the videos to view better.
2.2 Enhancing Baselines
Integrating FastGS into various baseline architectures significantly accelerates their training process.
3. Method Overview
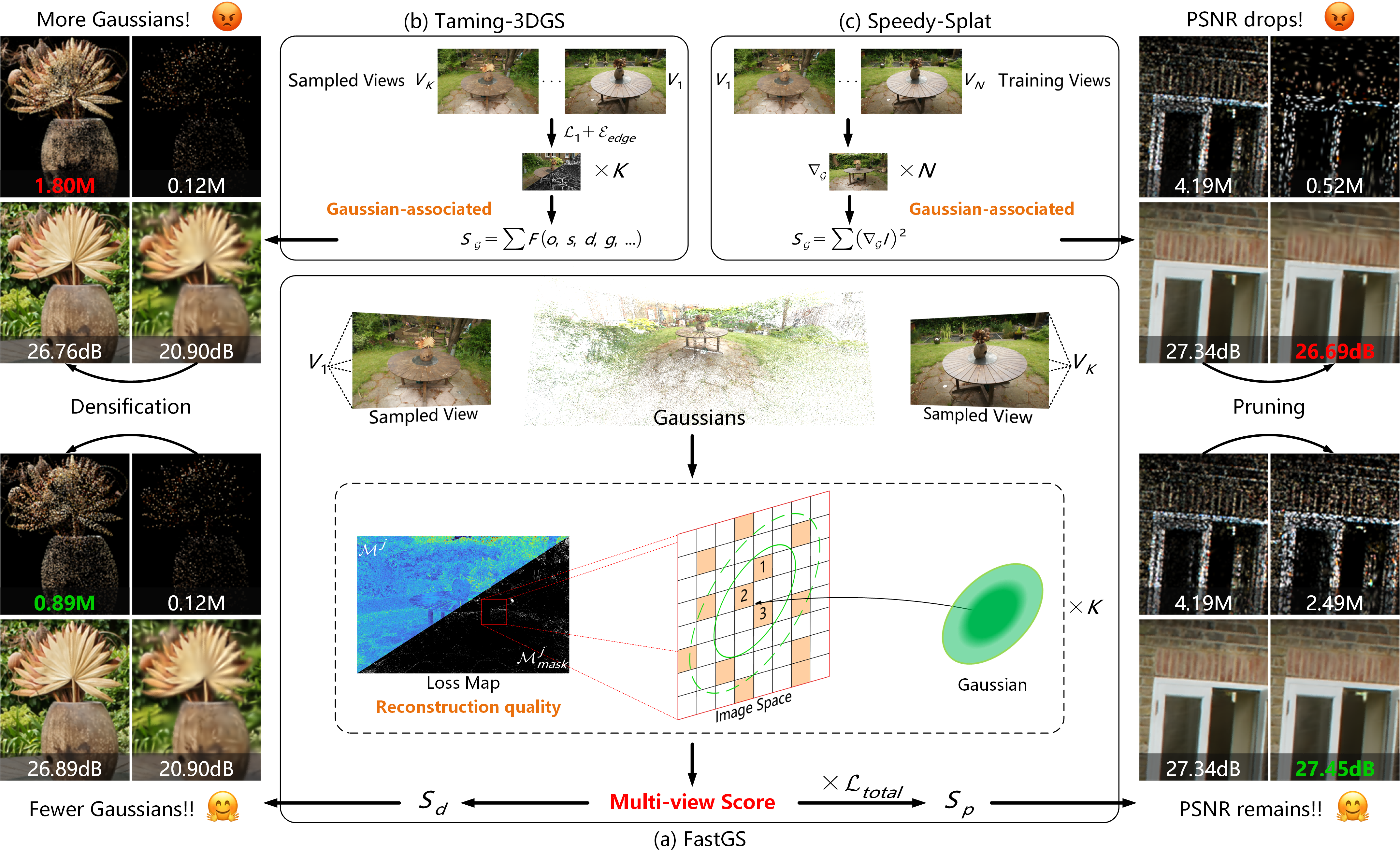
The FastGS pipeline rethinks importance estimation for Gaussians using multi-view consistency. We sample training views and build per-pixel L1 loss maps to evaluate how each Gaussian contributes across views.
Key components:
- ADC redesign: compute a multi-view score for each Gaussian by counting high-error pixels inside its 2D footprint — this drives densification and pruning.
Other SOTA 3DGS methods:
- (a) Taming-3DGS: estimates importance from per-Gaussian properties aggregated across sampled views — this can produce a larger number of redundant Gaussians, increasing memory and compute cost.
- (b) Speedy-Splat: computes Gaussian scores by accumulating Hessian-like approximations over training views, which may harm rendering fidelity.
The figure shows densification (from 0.5K to 15K iterations) on the left and pruning results (achieved using Speedy-Splat's pruning strategy and VCP on vanilla 3DGS) on the right, illustrating how FastGS preserves quality while reducing compute.
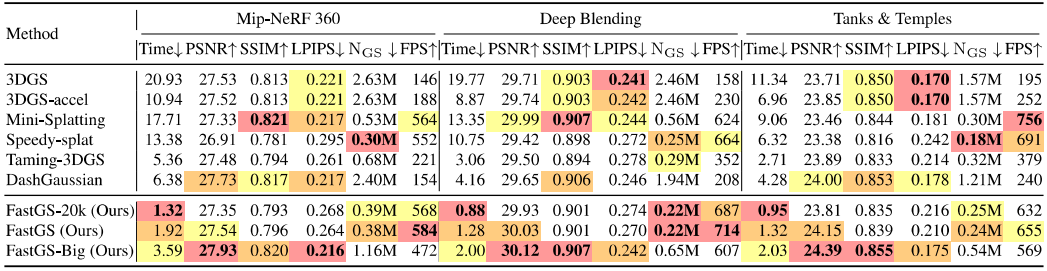
4. FastGS Improving SOTA
Quantitative comparisons show that FastGS completes 3DGS training in about 100 seconds on average while keeping rendering quality comparable to prior fast-optimization methods.
- FastGS-Big: achieves the best rendering quality among tested methods and still trains faster than the previous SOTA.
- Measurements: time is reported in minutes for easier comparison across methods.